
本方案以 DeepSeek-R1 满血版为例进行演示,通过阿里云百炼模型服务进行 DeepSeek 开源模型调用,可以根据实际需求选择其他参数规模的 DeepSeek 模型。阿里云百炼平台提供标准化接口,无需自行搭建模型服务基础设施,且具备负载均衡和自动扩缩容机制,保障 API 调用稳定性。搭配 Chatbox 可视化界面客户端,进一步简化了调用流程,无需在命令行中操作,通过图形化界面即可轻松配置和使用 DeepSeek 模型。
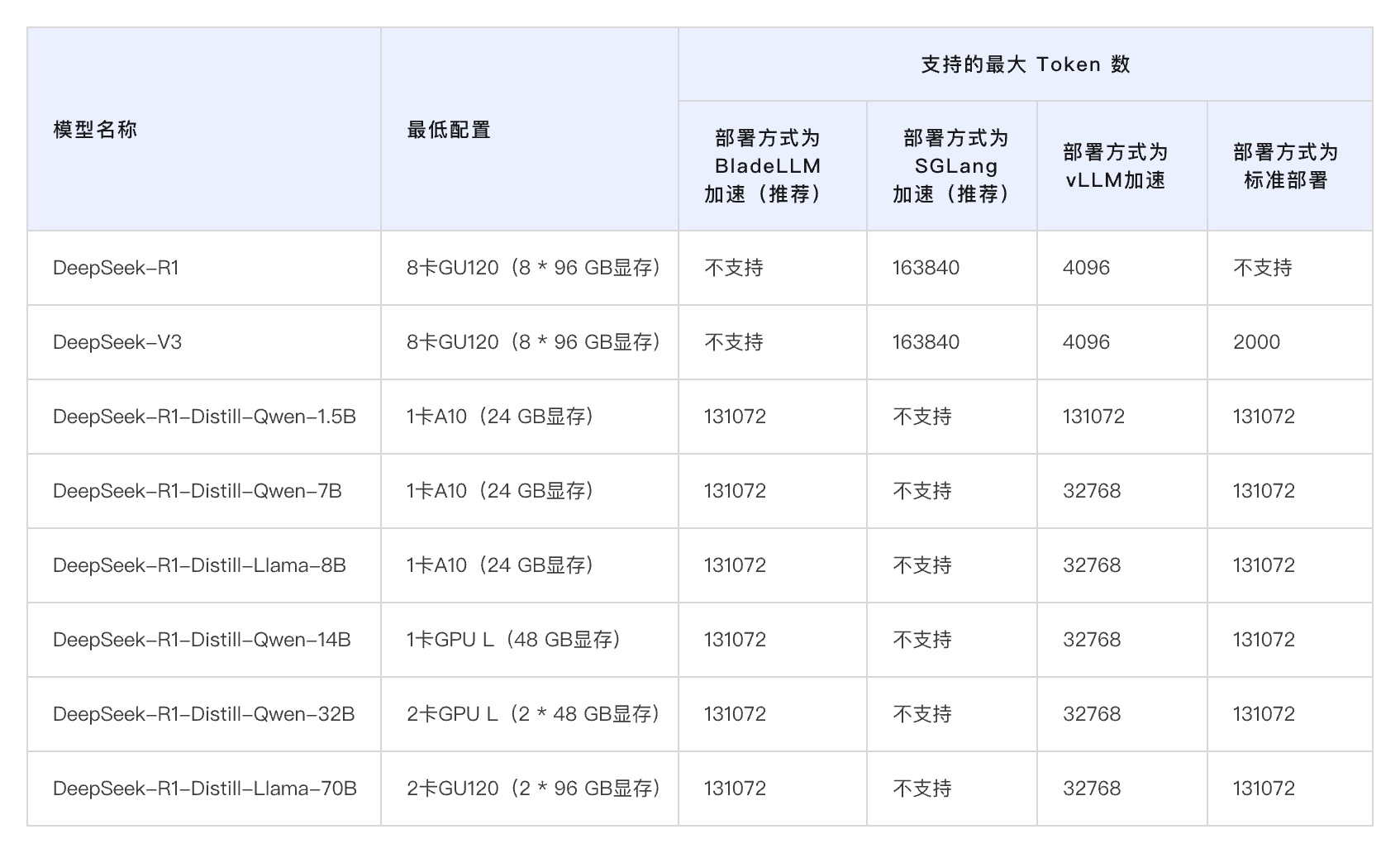
本方案无须编写代码,可一键部署 DeepSeek 系列模型。本方案以 DeepSeek-R1-Distill-Qwen-7B 为例进行演示,用户通过人工智能平台 PAI 的 Model Gallery,无须写代码即可完成模型部署。用户也可以在 PAI-Model Gallery 中选择 DeepSeek-R1 等其他模型进行一键部署,系统将自动适配所需的实例规格。同时,对于希望自持模型的用户,PAI-DSW 和 PAI-DLC 可支持 DeepSeek 系列模型的微调训练,以满足企业特定的场景需求。适用于需要一键部署,同时需要推理加速、支持并发的用户。

本方案介绍如何快速在 GPU 云服务器上,通过 vLLM 模型推理框架部署 DeepSeek-R1 满血版。凭借 GPU 云服务器的高性能并行计算能力,可以大幅加速大型模型的推理过程,尤其适用于处理大规模数据集和高并发请求场景,从而显著提升推理速度与吞吐量。若采用单机部署,在 GPU 服务器上单独部署 vLLM 推理服务,并加载所需的大规模模型,从而提供标准化的 OpenAPI 接口服务。若采用集群部署,将利用 Ray Cluster 来实现高效的分布式计算,支持 vLLM 推理服务的部署以及大规模模型的加载。

提供高效的数学问题求解工具,支持复杂公式推导、统计分析及数据建模,显著提升科研、工程及金融领域的数学建模与数据分析效率。

自动化生成高质量代码片段,优化现有代码性能,实时检测并修复代码错误,助力开发者在软件工程、算法设计等领域提升开发效率与代码可靠性。

具备强大的逻辑推理与语义理解能力,支持问答系统、知识推理等任务,广泛应用于智能客服、知识管理等领域,提升对复杂文本的理解与推理效率。




