 深度湖仓融合
深度湖仓融合SelectDB 深度融合 Iceberg、Paimon 等开放湖仓格式,结合向量化执行引擎、物化视图和现代化的查询优化器,能够获得极佳的湖仓数据分析体验。
 丰富的数据源连接器
丰富的数据源连接器SelectDB 不仅支持 MySQL、PostgreSQL、Oracle、Clickhouse 等多种 JDBC 协议的数据库和湖仓系统,实现快捷的多数据源联邦分析,同时还具有 ZeroETL 能力。
 统一的多负载管理
统一的多负载管理基于无状态的计算节点,SelectDB 可以按需创建不同的计算组资源,在共享湖仓数据的同时,隔离计算资源,按需应对不同的业务负载需求。
| 对比项 | Trino/Presto | SelectDB |
|---|---|---|
| 物化视图 | 功能单一,依赖外部组件仅支持手动和全量的物化视图刷新,并且依赖开放湖格式提供存储能力。 | 增量更新和透明加速高效支持各个数据源的物化视图构建,以及物化视图的增量更新和查询透明加速能力,极大提升查询效率。 |
| 查询优化器 | 复杂查询优化效果差基于代价和规则的查询优化器,支持复杂SQL优化,但不支持统计信息的自动收集。 | 复杂查询精准优化基于代价和规则的查询优化器。拥有丰富的统计信息自动收集和采样能力,能够获得更精准的查询规划。 |
| 缓存能力 | 依靠第三方组件依赖外部组件如 Alluxio 提供缓存能力。 | 开箱即用内置基于内存和本地高速磁盘的数据缓存能力,并拥有丰富的缓存预热与淘汰策略。 |
| 应用场景 | 适用场景单一仅作为查询引擎。 | 适用场景丰富云原生数据仓库,内置高性能表格存储,既可支持低延迟的高并发查询,又可作为湖仓查询引擎进行交互式查询分析。 |
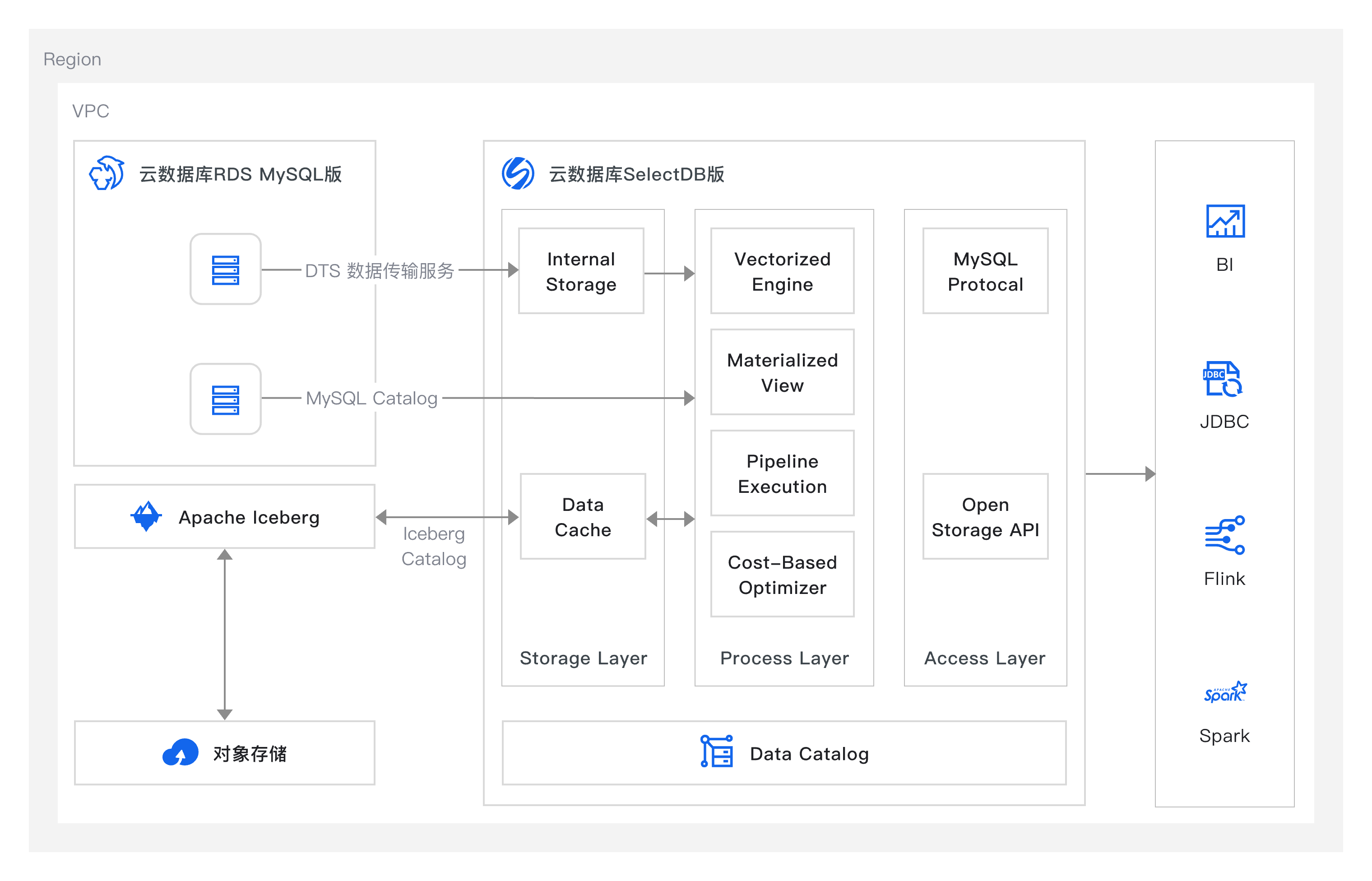
本方案通过 SelectDB 在 OSS(对象存储)上构建 Iceberg 湖格式的 TPC-H 100G 测试数据集,来验证 SelectDB 对于开放湖格式 Iceberg 的数据写入能力和分析加速能力。同时,通过 DTS(数据传输服务)将云数据库 RDS MySQL 版实例中的业务数据实时同步到 SelectDB 中,并利用 SelectDB 的异步物化视图和透明改写的功能,进行 SelectDB 内表、MySQL 表、Iceberg 表的联邦分析查询和多数据源的轻量级 ETL。通过湖仓分析加速、湖仓数据处理和多源联邦分析三个典型场景,实现了基于 SelectDB 湖仓一体的最佳实践。

通过 SelectDB 直接访问存储在 OSS、HDFS上的 Iceberg、Paimon 格式的数据。并利用数据本地缓存、物化视图透明改写等技术,显著提升湖上数据分析性能。

利用 SelectDB 内置的多种连接器,将 Hive、Iceberg、Paimon、RDS 以及 SelectDB 内表数据关联查询,彻底解决数据孤岛问题,提升数据分析时效性,降低数据在不同系统间传输转换的成本。

利用 SelectDB 内置的多种连接器,将 Hive、Iceberg、Paimon、RDS 以及 SelectDB 内表数据关联查询,彻底解决数据孤岛问题,提升数据分析时效性,降低数据在不同系统间传输转换的成本。




